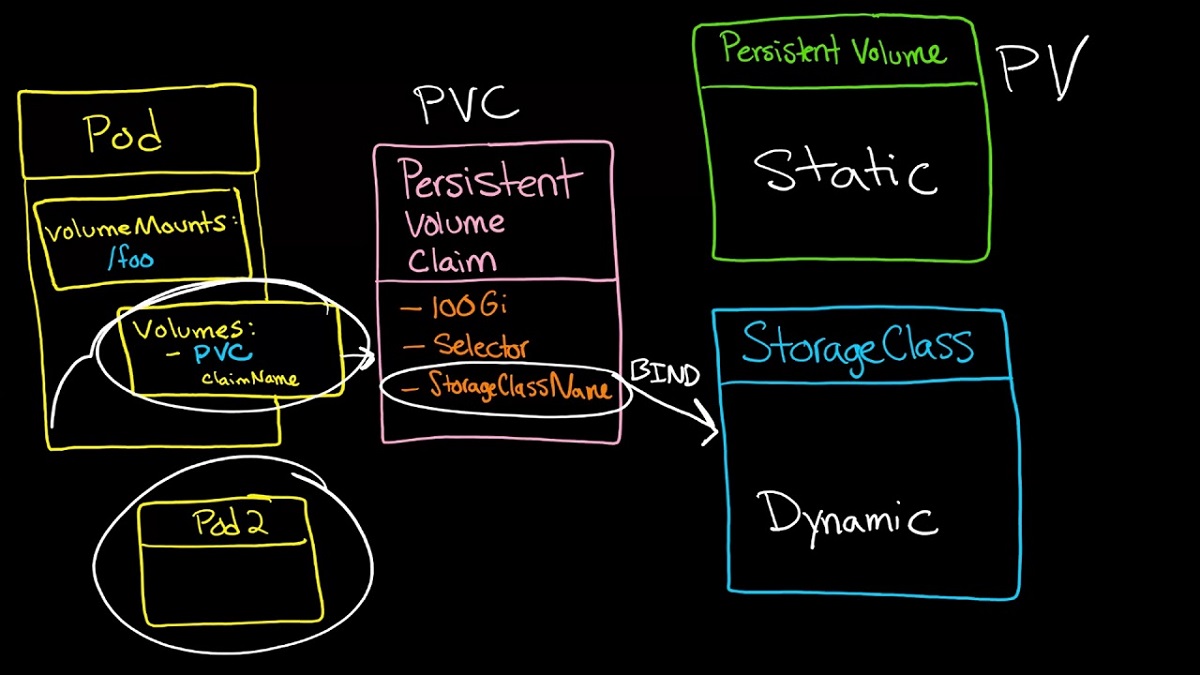
A persistent volume (PV) is a storage device mounted into Pods. When the Pod is deleted, the content remains on the PV. A PersistentVolumeClaim requests a storage resource that your deployment can claim. It specifies a size, access mode and StorageClass.
The cluster must have a valid data source and a volume plugin installed for a PVC to be created. Warning Events are generated on the PVC if these components are missing.
Protection of important data.
Persistent volumes make it easy for developers to build scalable applications. However, when using persistent storage, it’s important to follow best practices to protect data from unauthorized access. This includes implementing proper access controls, using the right policies and configurations, and ensuring that only authorized users can access critical data.
The Kubernetes architecture uses Persistent Volume Claims (PVCs) to provision storage on the cluster. A PVC identifies a specific set of storage requirements and specifies a unique identifier for the volume that is bound to it. The group uses this identifier to determine if the selected book matches the needs, including access modes and the requested storage size.
A PVC can be statically or dynamically created in your cluster. If a PVC specifies a StorageClass, the group will use a plugin to provide storage based on those requirements.
Each StorageClass can have different reclaim policies, including Retain and Delete.
When the application is done with a particular volume, it can delete the PVC object through the API to allow the storage reclamation.
It’s also important to note that a PVC must be bound to a PV before Pods can use it. This prevents Pods from attempting to use an unclaimed volume and possibly running into issues. This issue can occur when the PVC cannot find a matching PV or when the PVC is not configured correctly.
Data independent of pods.
Persistent volumes are an excellent option when you need to add storage for data that is not tied to the lifecycle of a container. They are independent of pods and the underlying storage devices, allowing them to survive Pod restarts and to be shared among multiple containers.
In addition, a Kubernetes persistent volume outlives individual pods, enabling safe and easy data recovery even when Pods are deleted. A Pod must request one through a PersistentVolumeClaim (PVC) to use a persistent volume. The PVC specifies the storage capacity and characteristics that the Pod requires, and the cluster matches it with an available constant book. A PVC may also select a single access mode, which limits the number of pods that can read or write to it. The reclaim policy for the volume determines what happens to it after the Pod is deleted.
There are several types of persistent volumes: fc, local, and cloud.
The FC volume type allows you to mount an existing Fibre Channel block storage volume in a Pod. You can create a scalable solution for high-performance applications such as content management systems and file sharing. The local volume type mounts a file or directory from the host node’s file system in your Pod. This allows you to create a durable, portable data solution without manually scheduling your pods to nodes. However, if the host node fails or becomes unhealthy, the local volume can become inaccessible, resulting in potential data loss.
Scalability.
For stateful applications, persistent storage is critical.
While ephemeral volumes provide some protection, they can be easily deleted from the underlying disk and, therefore, are unsuitable for all applications.
Persistent volume storage is highly scalable and offers data durability and redundancy, ensuring application availability. This makes it a great choice for databases and other mission-critical applications. Many different storage technologies can back persistent volumes, providing developers the flexibility to meet their scalability requirements. In addition, Kubernetes supports multiple access modes, allowing developers to choose the best option for their specific use cases, such as read-only or read/write.
To scale a persistent volume, developers create a PersistentVolumeClaim object that specifies the size and access mode of the desired storage. This can be done either statically or dynamically. The cluster examines the PersistentVolumeClaim to find a storage object that satisfies the claim.
If a PersistentVolumeClaim meets the requirements for the specified storage type, the group will mount that volume in the Pod. Persistent books are independent of the life cycle of a pod or node, making them easier to manage in terms of backups, performance, and capacity allocations.
In addition, they include safeguards to protect against accidental deletion of data. Depending on your storage needs, you can choose from many popular solutions for persistent volumes, such as Network File Systems, Amazon Elastic Block Store (EBS), Google Persistent Disk, and Azure disk storage.
Backups.
The Pods accessing Persistent Volumes are known as consumers. Consumers can be either Static or Dynamic. Administrators bind storage that they think Pods will need when using static provisioning before the users request it. In contrast, dynamic provisioning enables users to directly request the type of storage and access permission they need.
The Devs ask for the repository by creating a PersistentVolumeClaim that specifies the volume size, access mode and data type. The Admins then prepare and provision the requested PersistentVolume (PV) by matching it with the available StorageClass.
If a PVC does not specify the storageClassName field, the control plane will automatically check it with the default StorageClass in the cluster environment. This prevents a new PV from being created for every Pod that needs storage until the default StorageClass becomes available.
When a PersistentVolumeClaim is modified to request a larger volume, the underlying StorageClass will expand the existing PV. The PVC will remain bound to the underlying PV until the StorageClass is unbound from the Pod or until the PVC is deleted. Backups are a best practice for Kubernetes and can be implemented with the OpenShift APIs for Data Protection (OADP). OADP is an operator that lets you back up all resources in a project, including persistent volumes.
Leave a Reply